VGG16 ARCHITECTURE
INTRODUCTION:
VGG16 is a 16 layer convolutional neural networks introduced by Visual Geometry Group(VGG),hence the name VGG16.VGG16 is the winner of IMAGENET competition in 2014. It is one of the pretrained convolutional neural network architecture and state of the art of deep learning algorithms. The vgg16 architecture comprises of convolutional layers ,maxpooling layers and fully connected layers. It uses various filters and same kernels to extract features from the image.
ARCHITECTURE:
VGG16 architecture consists of 16 layers ie, five blocks .it
has two convolutional layers in the first two block and three convolutional
layers in the next three blocks.It uses 64 filters in the first block,128
filters in the second block,256 filters in the third block and 512 filters in
the fourth and fifth blocks respectively.The kernel size 3x3 is used for all
convolutional layers and 2x2 is used for all maxpooling layers.It uses stride 1
for convolutional layers and stride 2 for maxpooling layers. VGG16 architecture
uses relu activation function for all layers and softmax for the ouput layer.



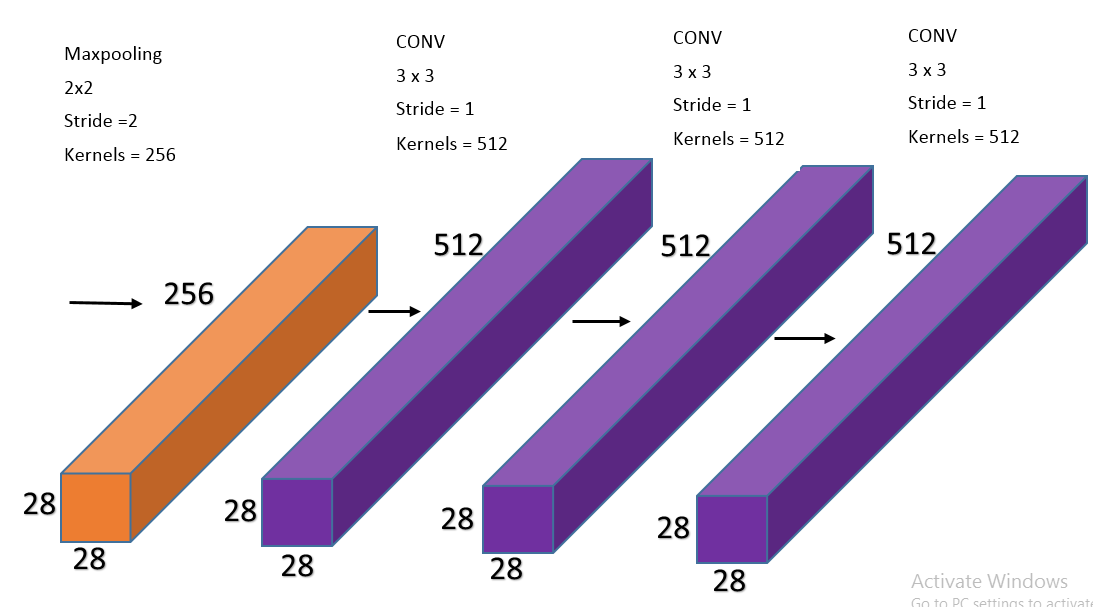


The input image is of dimensions 224x224x3. Here, 3 represents the RGB image,hence the channels in the input image is 3. VGG16 architecture consists of five blocks. The first block consists of two convolutional layers of 64 filters ie,64 feature maps with kernel size of (3,3) and same padding with stride 1.Then it is followed by a maxpooling layer with size of (2x2) with stride 2.The image dimensions reduced to 112x112x64 after the maxpooling output.The second block consists of two convolutional layers with 128 filters of kernel size (3x3) and same padding with stride 2.This followed by a maxpooling layer with the size of (2x2) with stride 2.The input to the third block is the output of maxpooling layer with image dimensions 56x56 of 128 feature maps.The third block consists of three convolutional layers with 256 filters of kernel size (3x3) and same padding with stride 2.Then it is followed by a maxpooling layer with the size of (2x2) with stride 2.The input to the fourth block is the output of maxpooling layer with image dimensions 28x28 of 256 feature maps. The fourth block consists of three convolutional layers with 512 filters of kernel size (3x3) and same padding with stride 2.Then it is followed by a maxpooling layer with the size of (2x2) with stride 2.The input to the fifth block is the output of maxpooling layer with image dimensions 14x14 of 512 feature maps. The fifth block consists of three convolutional layers with 512 filters of kernel size (3x3) and same padding with stride 2.Then it is followed by a maxpooling layer with the size of (2x2) with stride 2.Finally the output of maxpooling layer with image dimensions 7x7 of 512 feature maps.We flatten 7x7x512 feature maps to get 25088 feature vectors.then it is passed through three fully connected layers.The first and second fully connected layers comprises of 4096 feature vectors with dimension 1.The third fully connected layer comprises of 1000 ouputs with softmax function.Finally VGG16 contains a trainable parameters of 134,264,641 in it.
Thank you for a detailed information.
ReplyDelete